
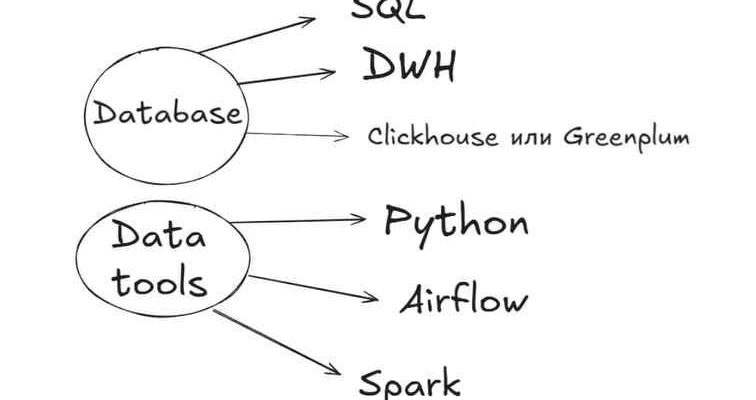
Дорожная карта (roadmap) Data Engineer или Analytics Engineer.
Этот стек технологий — классический набор современного Data Engineer или Analytics Engineer. Изучать всё сразу может быть трудно, поэтому лучше двигаться от фундамента к сложным распределенным системам.
Вот подробный роадмап, разделенный на логические этапы.
Этап 1: фундамент (SQL и Python).
Без свободного владения этими инструментами двигаться дальше не имеет смысла, так как они используются во всех остальных технологиях из списка.
SQL ( must-have):
- Базовые запросы (SELECT, WHERE, GROUP BY, HAVING).
- Типы JOIN и работа с NULL.
- Обязательно: Оконные функции (RANK, ROW_NUMBER, LAG/LEAD).
- Понимание планов выполнения запросов (EXPLAIN) и индексов.
Python:
- Синтаксис, типы данных, циклы и функции.
- Работа с библиотеками pandas или polars (обработка данных в памяти).
- Написание скриптов для работы с API и базами данных (библиотеки psycopg2, sqlalchemy).
Этап 2: теория DWH и моделирование.
Прежде чем переходить к мощным базам вроде ClickHouse, нужно понять, как правильно структурировать данные.
DWH (Data Warehouse):
- Архитектура: слои данных (Raw, Staging, Core, Marts).
- Моделирование: Схема «Звезда» и «Снежинка», таблицы фактов и измерений.
- Подходы Кимбалла (Kimball) vs Инмона (Inmon).
- Понятие ETL (Extract, Transform, Load) и ELT.
Этап 3: продвинутые базы данных (MPP-системы).
Здесь вы выбираете инструмент в зависимости от задач (аналитика или хранение огромных объемов).
ClickHouse:
- Идеально для OLAP (быстрой аналитики).
- Понимание колоночного хранения данных.
- Движки таблиц (MergeTree, ReplicatedMergeTree).
Greenplum:
- Построена на базе PostgreSQL, но работает как MPP (массивно-параллельная архитектура).
- Понимание распределения данных (Distribution keys) и партиционирования.
- Совет: Начните с ClickHouse, если важна скорость аналитики, или с Greenplum, если нужна совместимость с экосистемой Postgres и сложная логика транзакций.
Этап 4: оркестрация и Big Data (Airflow и Spark).
Когда данных становится много, а процессов — сотни, их нужно автоматизировать и распределять.
Apache Airflow:
- Создание DAG (направленных ациклических графов).
- Операторы (PythonOperator, BashOperator, SQL-операторы).
- Управление расписанием и обработка ошибок.
Apache Spark:
- Работа с большими данными, которые не влезают в память одного компьютера.
- PySpark (Spark + Python).
- Понимание ленивых вычислений (Lazy evaluation) и трансформаций.
С чего начать прямо сейчас?
Если вы новичок, рекомендую следующий порядок:
- SQL до уровня уверенных джоинов и агрегаций.
- Python (библиотека Pandas).
- Развернуть ClickHouse локально через Docker и попробовать загрузить туда первый CSV-файл.


